Создание конвейера RAG с n8n
Создание конвейера RAG часто начинается с простой цели, но быстро становится сложнее, чем ожидалось. Небольшая функция может превратиться в коллекцию сервисов, скриптов и файлов конфигурации, где мелкие изменения вызывают частые сбои. То, что должно быть простым способом привязки модели к вашим собственным данным, оказывается погребенным под клеевым кодом и накладными расходами на развертывание, делая основную идею сложнее в работе. Именно здесь n8n с его возможностями RAG становится интересным. Вы строите весь конвейер RAG в одном визуальном рабочем процессе, выбираете свои модели и векторные хранилища и полностью избегаете клеевого кода. В результате получается более простой и надежный способ привязки ИИ к вашим собственным данным. Звучит интересно? Давайте рассмотрим подробнее, как это работает!
Почему RAG существует в принципе?
Перед обсуждением конвейера Retrieval-Augmented Generation (RAG) полезно задать простой вопрос: что именно идет не так, когда вы используете базовую модель самостоятельно? Большинство команд сталкиваются с знакомыми шаблонами:
- Модель галлюцинировала детали, которые не соответствуют реальности.
- Она не знала внутренних данных.
- Вы не могли легко обновить ее знания без переобучения модели.
Представьте, что у вашей компании есть документация по продуктам, тикеты поддержки и внутренние руководства. Вы задаете базовой модели вопрос вроде «Поддерживает ли наш корпоративный план SSO с провайдером X?». Модель понятия не имеет, что на самом деле входит в ваш план, поэтому она угадывает на основе шаблонов из общего интернета. Иногда это близко к истине, иногда это опасно неверно. Вам нужен способ предоставить модели свежий, надежный контекст в момент постановки вопроса. Вам также нужен способ делать это без переобучения модели каждый раз, когда меняется ваша документация. Это и есть идея конвейеров RAG.
Что такое конвейер RAG?
Конвейер RAG (Retrieval-Augmented Generation pipeline) — это система, которая помогает модели ИИ отвечать на вопросы, используя ваши собственные данные, а не только то, что она выучила во время обучения. Вместо того чтобы просить модель «знать все», вы позволяете ей:
- Извлекать наиболее релевантные фрагменты ваших собственных данных для заданного вопроса, на лету.
- Дополнять запрос, чтобы модель отвечала с этим контекстом перед собой.
Вы можете представить это как библиотекаря для вашей языковой модели. Ингессия — это когда вы приносите книги в библиотеку. Извлечение — это процесс поиска нужных страниц. Дополнение — это когда вы передаете эти страницы модели. В n8n каждый из этих этапов существует как узлы в одном рабочем процессе, а не разбросанные скрипты по сервисам.
Ключевые этапы конвейера RAG
Этап 1: Ингессия данных
Этот этап отвечает на вопрос «К какой информации должна иметь доступ моя модель?» Типичные источники включают документацию по продуктам, статьи базы знаний, страницы Notion, пространства Confluence, PDF в облачном хранилище или тикеты поддержки. Во время ингессии вы:
- Загружаете данные: Это этап, на котором вы подключаетесь к выбранному источнику и извлекаете документы, с которыми должна работать система.
- Разделяете данные: Длинные документы разбиваются на меньшие сегменты, чтобы их было проще обрабатывать модели.
- Встраиваете данные: Каждый фрагмент текста преобразуется в вектор с помощью модели встраивания.
- Храните данные: Векторы затем размещаются в векторной базе данных.
В ориентированных на код настройках это обычно требует нескольких скриптов и сервисов. В n8n многие из этих шагов существуют как готовые к использованию узлы.
Этап 2: Извлечение, дополнение и генерация
Извлечение: Когда пользователь задает вопрос, система преобразует этот вопрос в вектор с помощью той же модели встраивания, что использовалась во время ингессии. Этот вектор запроса затем сравнивается со всеми векторами в базе данных, чтобы найти ближайшие совпадения.
Генерация: Языковая модель получает две вещи: вопрос пользователя и релевантный текст. Она комбинирует оба ввода, чтобы произвести обоснованный ответ, используя извлеченную информацию как контекст для ответа.
Как построить конвейер RAG в n8n?
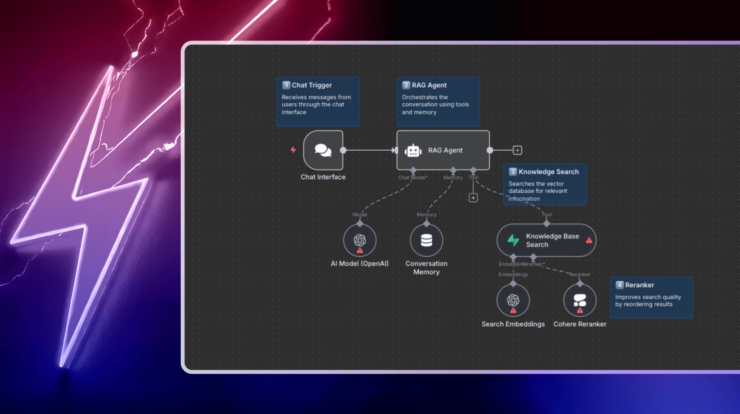
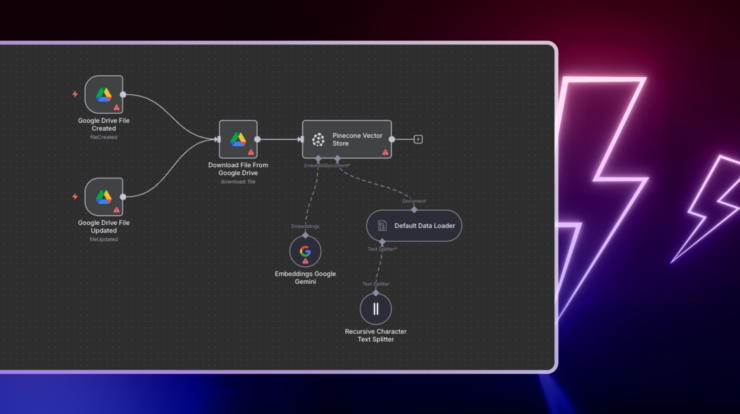
Мы используем n8n, чтобы проиллюстрировать практический, готовый к производству подход к созданию рабочих процессов RAG. Вот рабочий процесс n8n, который отслеживает новые или обновленные документы в Google Drive, автоматически их обрабатывает, хранит их встраивания в Pinecone и использует модели Google Gemini для ответа на вопросы сотрудников на основе этих документов. Все живет внутри одного визуального рабочего процесса. Вы настраиваете его. Вы не пишете шаблонный код.
Шаг 1: Подготовьте свои аккаунты
Вам понадобится три настроенных сервиса:
- Проект Google Cloud и Vertex AI API
- Ключ API Google AI
- Учетные данные Google Drive OAuth2
- Аккаунт Pinecone
Шаг 2: Подготовьте вашу папку Google Drive
Создайте выделенную папку в Google Drive. Эта папка будет содержать все документы, которые должен использовать ваш чат-бот в качестве ссылок. Рабочий процесс будет автоматически отслеживать эту папку.
Шаг 3: Добавьте свои учетные данные в n8n
Перед тем как рабочий процесс сможет запуститься, n8n нуждается в разрешении общаться с внешними сервисами. Вы делаете это, создавая учетные данные.
Шаг 4: Импортируйте рабочий процесс RAG
Скачайте или скопируйте рабочий процесс и импортируйте его в ваш экземпляр n8n.
Шаг 5: Настройте узлы
Обновите узлы Google Drive Trigger и подтвердите настройки модели встраивания в узле Embeddings Google Gemini.
Шаг 6: Протестируйте конвейер RAG
Добавьте или обновите документ, чтобы запустить поток индексации. Затем задайте вопрос через точку входа чата и наблюдайте, как агент извлекает релевантный текст и генерирует ответ.
Шаг 7: Активируйте рабочий процесс
Включите рабочий процесс в n8n Cloud или запустите его в вашей само-хостинговой среде.
Какие 5 примеров конвейеров RAG в n8n?
Теперь, когда вы увидели, как конвейер RAG вписывается в n8n, полезно посмотреть на реальные примеры:
- Шаблон RAG-стартера с использованием простых векторных хранилищ и триггера формы.
- Автоматическое создание пользовательских рабочих процессов с GPT-4o, RAG и веб-поиском.
- Создание бота-эксперта по документации с RAG, Gemini и Supabase.
- Базовый чат RAG для быстрого прототипирования.
- Локальный чат-бот с Retrieval Augmented Generation (RAG).
Преимущества и вызовы RAG
Преимущества
- Снижает галлюцинации, обосновывая ответы в ваших реальных данных.
- Позволяет легко обновлять без переобучения.
- Делает ваши знания повторно используемыми.
- Ускоряет эксперименты, позволяя менять модели или источники данных без переписывания кода.
Вызовы
- Зависимость от качества ваших данных.
- Может вводить задержку с большими документами.
- Необходимость учитывать безопасность данных.
Часто задаваемые вопросы о конвейерах RAG
Как конвейер RAG в LangChain сравнивается со строительством одного в n8n? LangChain дает вам полный контроль через код, в то время как n8n предлагает визуальный поток.
Могу ли я все еще использовать Python? Да, вы можете использовать Python для специфичных частей.
Нужен ли мне код вообще? Вам не нужен код для построения основного конвейера.
Как конвейер RAG на базе Haystack вписывается с n8n? Вы можете оставить Haystack для конкретной логики извлечения и позволить n8n обрабатывать окружающую оркестрацию.
Заключение
RAG существует, потому что базовые модели сами по себе не могут надежно отвечать на вопросы о ваших внутренних данных. В n8n вы используете готовые шаблоны и визуальные узлы, чтобы строить и развертывать конвейер RAG с минимальным кодом. Вы сохраняете контроль, ясность и гибкость без утопания в настройке.
Создайте свои собственные рабочие процессы RAG
Попробуйте n8n сейчас и стройте, тестируйте и развертывайте обоснованные рабочие процессы ИИ быстрее.
Полезные ссылки
- Заказ услуг по автоматизации
- Виртуальный хостинг Beget.
- Аренда сервера с n8n.
- Аренда VPN сервера от Beget.
- Доступ к 500+ LLM из РФ.
- Виртуальные карты для оплаты AI
Наши соц. сети
- Telegram канал ProDelo.
- Общий чат ProDelo.
- Бесплатный курс по n8n
- Наш Youtube канал
- Наш Яндекс Дзен канал
- Наша группа в ВК